Application Access
Simplified
One Click Access to applications with zero trust security framework for seamless user experience, better security controls, and reduced complexity

Recognised By Leading Analyst Firms and Market Leaders





Securing the 'Work from Anywhere' Experience is the Need of the Hour

How InstaSafe makes the difference?
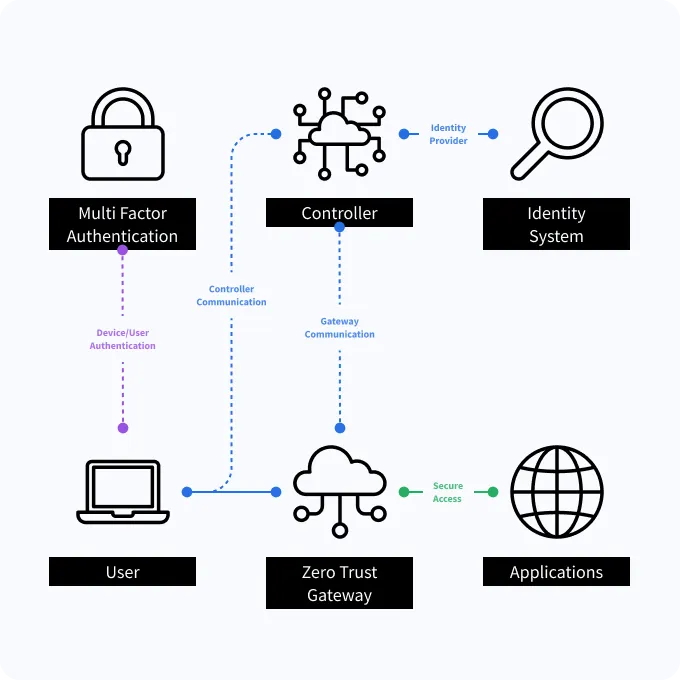
User and Device Authentication
User identity and user device gets authenticated by the Controller using Multi factor authentication
Controller and Gateway Communication
Controller communicating with Gateway with request to allow access for legitimate user
User Device to Gateway
mTLS tunnel gets established between device and Gateway to allow data traffic for specified application access
Our Approach to Zero Trust
Moving Beyond the “Castle and Moat” Security Model to Zero Trust Security

Authentication Before Access
Combine seamless integration with IDP and AD, with integrated MFA and SSO capabilities to ensure secure and seamless one click access to applications

Granular Access Controls
Set up access controls for applications, file and service access

Continuous monitoring of Network & device behaviour
Get 360 degree visibility with easy integration with SIEM Tools

Threat Intelligence and Alerts
Detect security events like invalid login attempts, bruteforce attacks; Check health of gateways and devices and provide alerts
Why InstaSafe Zero Trust?

Least Privilege Access
Leverage Granular Access Control and Role Based Access Policies to grant users the minimum access necessary to do their jobs

Segmented Application Access
Ensure that users can only access what they are allowed to access through application specific tunnels

Behavioural Authentication
Identify user impersonation attempts by analysing past user behaviours

One Click Secure Access
Combine seamless integration with IDP and AD, with integrated MFA and SSO capabilities to ensure secure and seamless one click access to applications
Privacy First
Authenticate user and device identity without routing any customer data through vendor owned infrastructure, ensuring data privacy

Drop All Firewall
All data traffic coming to the IP is dropped, to avoid detecting presence of the IP address

Server Blackening
Reduce your exploitable attack surface by making your assets completely invisible to the internet

Multi-Device Support
Secure access to any on-premise or cloud based application, and grant secure access to any type of device.
Secure Remote Access
Secure Cloud Access
DevOps Security
VPN Alternative
Clientless Remote Access

Access Remote Collaboration Applications: Improve workforce productivity with fast, direct, and secure access to all collaboration apps from a single dashboard
Extend Compliance for Remote Users: Extend AD/IDP compliance to all users and applications, no matter where they are
Monitor all network activity with Zero Trust Framework: Configure access policies and monitor all network activity from a single dashboard
Secure Remote Access
Access Remote Collaboration Applications: Improve workforce productivity with fast, direct, and secure access to all collaboration apps from a single dashboard
Extend Compliance for Remote Users: Extend AD/IDP compliance to all users and applications, no matter where they are
Monitor all network activity with Zero Trust Framework: Configure access policies and monitor all network activity from a single dashboard
Secure Cloud Access
Access Remote Collaboration Applications: Improve workforce productivity with fast, direct, and secure access to all collaboration apps from a single dashboard
Extend Compliance for Remote Users: Extend AD/IDP compliance to all users and applications, no matter where they are
Monitor all network activity with Zero Trust Framework: Configure access policies and monitor all network activity from a single dashboard
DevOps Security
Access Remote Collaboration Applications: Improve workforce productivity with fast, direct, and secure access to all collaboration apps from a single dashboard
Extend Compliance for Remote Users: Extend AD/IDP compliance to all users and applications, no matter where they are
Monitor all network activity with Zero Trust Framework: Configure access policies and monitor all network activity from a single dashboard
VPN Alternative
Access Remote Collaboration Applications: Improve workforce productivity with fast, direct, and secure access to all collaboration apps from a single dashboard
Extend Compliance for Remote Users: Extend AD/IDP compliance to all users and applications, no matter where they are
Monitor all network activity with Zero Trust Framework: Configure access policies and monitor all network activity from a single dashboard
Clientless Remote Access
Access Remote Collaboration Applications: Improve workforce productivity with fast, direct, and secure access to all collaboration apps from a single dashboard
Extend Compliance for Remote Users: Extend AD/IDP compliance to all users and applications, no matter where they are
Monitor all network activity with Zero Trust Framework: Configure access policies and monitor all network activity from a single dashboard
Benefits of Zero Trust Security
Enhanced Security
Only Authenticated Users and Authorized Devices are able to 'see' and access applications with zero trust security
Better Visibility
Gain a Bird’s eye view over all network traffic with zero trust model and identify threat vectors in real time
Simplified Access Control
Role based access to business applications on a need to know basis. One Click Access for better user experience
Simplified Deployment and Hyper scalability
Hardware Free. Rapidly deployable, scale as you go solutions
Our Customers Say on 





Hariharan S
Vice President
"Good to use, easy to manage Zero Trust VPN security tool for cloud and ERP applications"
InstaSafe has been instrumental in supporting the Information Management strategy of my organization by providing a secure foundation for our hybrid network infrastructure. We have managed to easily extend always-on connectivity and secure access to our cloud and ERP applications with Instasafe Zero Trust Access. It is much faster than a VPN and much easier to manage.
Seamless Support for your Stack
InstaSafe integrates seamlessly with every internal applications, databases, and cloud








Solve your access challenges with InstaSafe
Improve your security posture and gain better control over your network with Zero Trust



Webinar
Ensuring a Secure Work From Home Environment: Remote Access Security Best Practices
Watch WebinarOur Security Solutions are
Trusted by 150+ businesses of all industries and sizes







